
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- baekjun
- Algorythm
- 파이썬
- 라즈베리파이
- nav-tab
- MongoDB
- 라즈베리파이3b+
- 2909
- algotythm
- 알고리즘
- Python
- NAV
- 13237
- 2579
- CSS
- 라즈베리파이3
- Crawling
- node.js
- springboot3.x
- dynaminprogramming
- HTML
- 라즈비안
- bootstrap
- 크롤링
- dp
- 트리
- 16.04
- raspberrypi
- 백준
- ubuntu
- Today
- Total
노트
파이썬을 이용한 유튜브 채널 크롤링, csv파일로 만들기 본문
안녕하세요!
과제에 사용할 데이터를 뽑으려고 크롤러를 만들었습니다.
데이터는 제목, 동영상의 길이, 채널명, 구독자 수,
조회수, 올린지 얼마나 되었는지(업로드 시점), 그리고 현재 시간
이렇게 총 7종류를 뽑았습니다.
저는 BeautifulSoup4를 사용했고,
스크롤을 내려 더 많은 데이터를 뽑기 위해서 Selenium도 사용하였습니다.
.
먼저 데이터를 뽑고싶은 유튜브 채널을 켜줍니다.
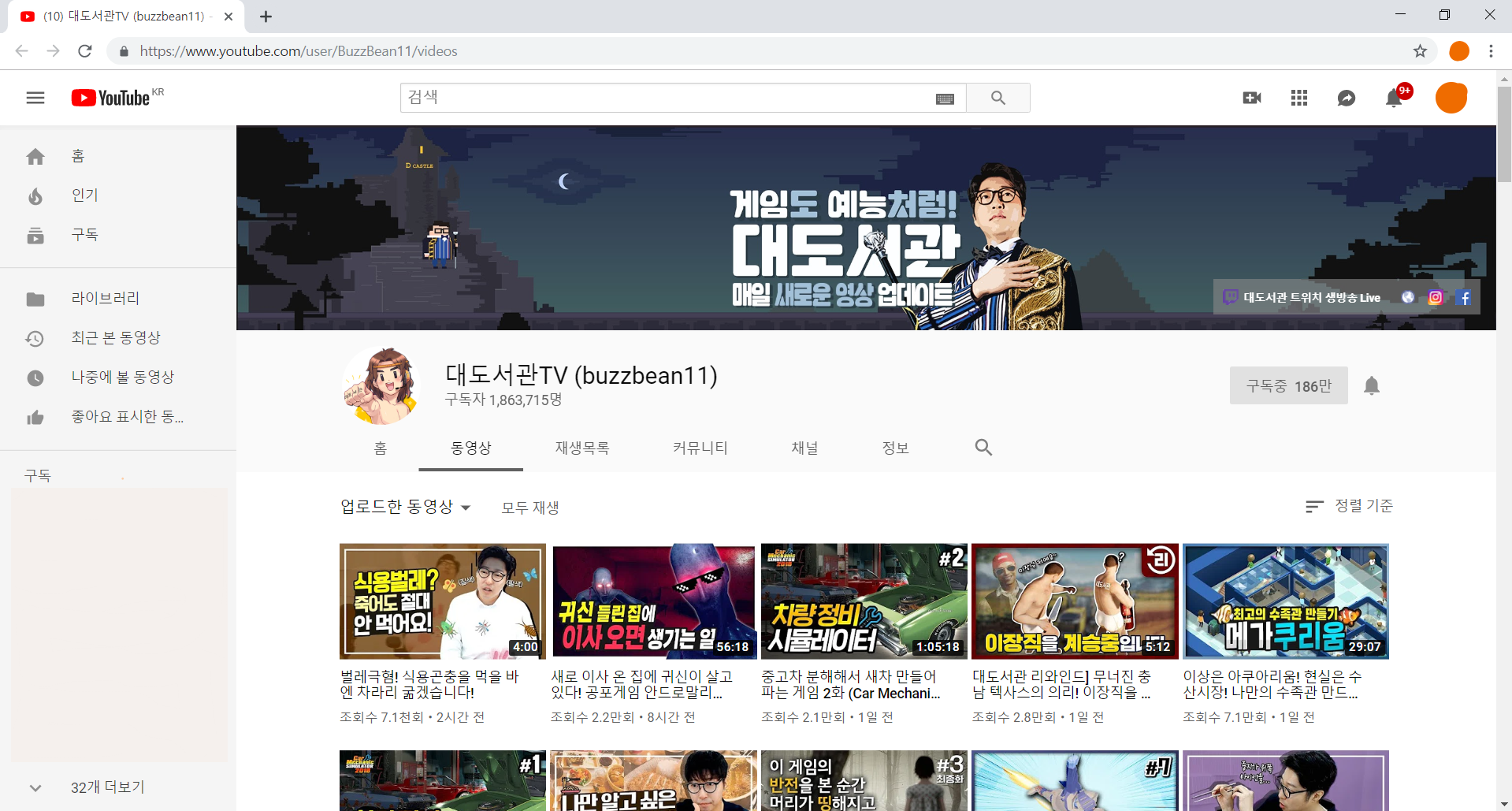
이제 이 페이지의 코드를 뽑아볼건데
뽑기 전에 Selenium에서 사용할 chromedriver를 설치해 줍니다.
링크에 들어가면 크롬 버전이 여러 개 있는데
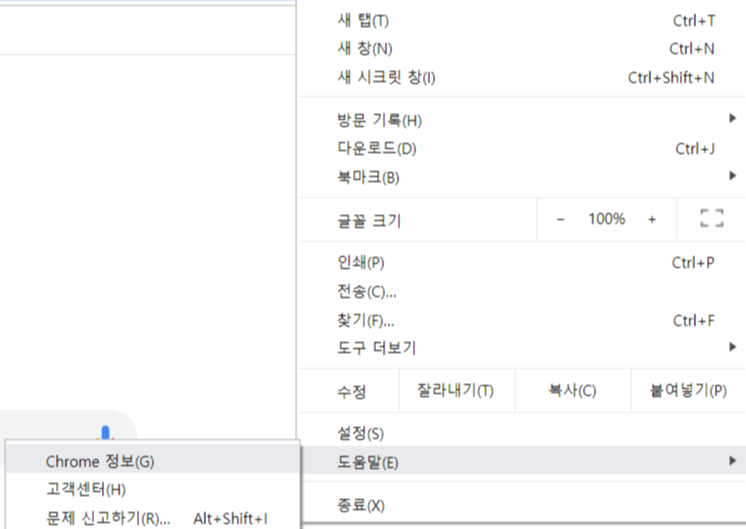
크롬정보에 들어가면 버전을 알 수 있습니다.
다운로드 받고 경로를 기억해 둡니다.
Selenium을 사용한 이유는
스크롤을 내리지 않고 그냥 코드를 뽑으면 데이터의 양이 너무 적기 때문입니다. (30개 정도)
일단은 아직 스크롤을 내리지 않고 그냥 링크만 열겠습니다.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome('"파일 경로"/chromedriver.exe')
driver.get('https://www.youtube.com/user/BuzzBean11/videos')
page = driver.page_source
page
코드를 실행하면 위 사진처럼 페이지의 코드가 나옵니다.
이제 bs4를 이용하여 이전 코드에서 뽑은 'page'를 BeautifulSoup을 사용한 'soup'으로 만들어줍니다.
그리고 위 사진을 보시면 제가 드래그한 제목 부분이
a태그 안의 class = yt-simple-endpoint style-scope ytd-grid-video-renderer라는
부분에 있는 것을 볼 수 있습니다.
find_all함수를 이용하여 'a'태그의 class가 "yt-simple-endpoint style-scope ytd-grid-video-renderer"인
데이터들만 뽑습니다.
from bs4 import BeautifulSoup
...
soup = BeautifulSoup(page,'lxml')
all_title = soup.find_all('a','yt-simple-endpoint style-scope ytd-grid-video-renderer')
title = [soup.find_all('a','yt-simple-endpoint style-scope ytd-grid-video-renderer')[n].string for n in range(0,len(all_title))]
title
그리고 비슷한 방법으로
나머지 데이터들도 뽑아보겠습니다.
* 동영상의 길이
...
all_video_time = soup.find_all('span','style-scope ytd-thumbnail-overlay-time-status-renderer')
video_time = [soup.find_all('span','style-scope ytd-thumbnail-overlay-time-status-renderer')[n].string.strip() for n in range(0,len(all_video_time))]
video_time
.
* 현재 시간을 제외한 나머지 데이터들
...
#채널명
chennel = soup.find('span','style-scope ytd-c4-tabbed-header-renderer').string
#구독자 수
sub_num = soup.find('yt-formatted-string','style-scope ytd-c4-tabbed-header-renderer').string
#조회수, 올린지 얼마나 되었는지(업로드 시점)
c = soup.find_all('span','style-scope ytd-grid-video-renderer')
view_num = [soup.find_all('span','style-scope ytd-grid-video-renderer')[n].string for n in range(0,len(c))].
여기서 조회수와 업로드 시점은 같은 'span'태그로 둘러싸여있고
class도 같아서 뽑힐 때
[ '1번동영상의 조회수',
'1번동영상의 업로드 시점',
'2번동영상의 조회수',
'2번동영상의 업로드 시점',
.
. ]
이런 식으로 나옵니다.
그런데 저는 for문을 이용하여 이중리스트에
이 데이터들을 저장할건데 그냥 for문을 돌리면 데이터가
[ ['1번동영상의 제목','1번동영상의~',...'1번동영상의 조회수'],
['2번동영상의 제목','2번동영상의~',...'1번동영상의 업로드 시점'],
['3번동영상의 제목','3번동영상의~',...'2번동영상의 조회수'],
.
. ]
이런식으로 섞여서 나오므로
for문에서 이 데이터들을 정리하도록 하겠습니다.
.
* 현재 시간
from time import localtime, strftime
...
#현재 시간
extract_date = strftime("%Y/%m/%d %H:%M:%S", localtime())
extract_date
#결과 : 2019/05/20 20:36:49time을 이용하여 현재 시간을 가져옵니다.
.
* 데이터 합치기
...
youtube_video_list = []
x = 0 #조회수의 index
y = 1 #업로드 시점의 index
for i in range(0,len(all_title)):
roww = []
roww.append(title[i])
roww.append(video_time[i].strip())
roww.append(chennel)
roww.append(sub_num)
roww.append(view_num[x])
x += 2 #조회수만 append
roww.append(view_num[y])
y += 2 #업로드 시점만 append
roww.append(extract_date)
youtube_video_list.append(roww) #2차원 list로 만들어줌
youtube_video_list이런식으로 for문을 돌리면

이렇게 깔끔하게 리스트로 정리됩니다.
이제 여기에 스크롤을 추가해 줍니다.
맨 처음에 작성한 코드에서 Selenium으로 end키를 5번 눌러주면 대략 90개 정도의 데이터가 뽑힙니다.
...
driver = webdriver.Chrome('C://chromedriver.exe')
driver.get('https://www.youtube.com/user/BuzzBean11/videos')
#여기서부터
time.sleep(5)
endk = 5
while endk:
driver.find_element_by_tag_name('body').send_keys(Keys.END)
time.sleep(0.3)
endk -= 1
#여기까지
page = driver.page_source
...처음에 sleep을 주는 이유는 사이트가 충분히 로드 될 시간을 주기 위해서 입니다.
이런 식으로 스크롤을 내릴 수 있습니다.
.
마지막으로 csv를 사용하여 지금까지 뽑은 데이터들을 csv파일로 뽑아보겠습니다.
import csv
...
csvfile = open("경로/파일명.csv","w",newline="")
csvwriter = csv.writer(csvfile)
for row in youtube_video_list:
csvwriter.writerow(row)
csvfile.close()

쨘
이렇게 csv파일로 만들어집니다.
.
.
<참고한 글들>
'코딩 > Python' 카테고리의 다른 글
| 파이썬 random() 사용하기 (0) | 2020.02.15 |
|---|---|
| 주피터 노트북 꿀팁 (0) | 2020.02.14 |
| [Python] Selenium으로 중고나라 크롤링 후 MySQL에 저장 (4) | 2020.01.11 |


